

跳脫 FP 的容器世界,今天想輕鬆一點,今天想介紹的是 Generator function,而 Generator function 為什麼會和 FP 有關呢?
在 FP 的世界裡,重要的是管理副作用,而 FP 管理副作用的方式之一就是「延遲副作用的執行」,也就是 Lazy evaluation (惰性求值),簡單說就是需要的時候才執行、才計算,而如果這個要執行的事情是會產生副作用的,我們就可以讓副作用晚點發生、只在我們需要的時候發生,以此管理副作用。而 JavaScript 的 generator function 就是個惰性求值的實際案例,除了因為自己想好好認識 generator function 外,也因為想了解惰性求值如何實作,所以今天選了這主題~
首先稍微介紹一下惰性求值的意思。在程式設計中,程式語言的求值策略(Evaluation Strategy)決定了表達式(expressions)在何時以及如何被計算。而大多數我們熟悉的程式語言,包括 JavaScript,其預設的策略都是 Eager Evaluation(及早求值,或稱貪婪求值)。
Eager Evaluation 意思是,一個表達式一旦被賦值給一個變數,它就會立刻、馬上被計算出結果。
const heavyComputation = () => {
console.log('正在進行非常耗時的計算...');
// 模擬一個複雜的運算
let sum = 0;
for (let i = 0; i < 1e9; i++) {
sum += i;
}
return sum;
};
const result = heavyComputation(); // '正在進行非常耗時的計算...' 馬上被印出
console.log('程式的其他部分...');
// 假設我們在某個條件下才需要用到 result
if (false) {
console.log(result);
}
在這個例子中,即使 if (false) 區塊內的程式永遠不會執行,heavyComputation() 依然在呼叫時就立刻執行運算,我們消耗了大量的 CPU 資源和時間,去計算一個根本用不到的結果。這就是「及早求值」的特性——不論你將來用不用得到,只要你呼叫我執行,那就先算了再說。(不過換個角度想,也許可以把 const result = heavyComputation() 移到 if 內執行 👀,但這就變成開發者需要手動管理執行時機,而我們希望的是一種更系統性的策略。)
而 Lazy Evaluation(惰性求值),又被稱為「call-by-need」,則採取了不同的策略:非到最後一刻,絕不進行任何計算(我就懶😇)。只有當某個值被真正需要時,計算才會發生。
在 JavaScript 中,我們可以用一個簡單的模式來模擬 Lazy Evaluation,那就是「thunk」,這是一個將表達式包裹在函式中的技巧,用以延遲其執行。這概念其實就和我們之前提過的 IO Functor/Monad 相同,將要執行的運算包在 IO 裡,但實際上還沒執行。
const heavyComputation = () => {
console.log('正在進行非常耗時的計算...');
//...同樣的耗時運算
let sum = 0;
for (let i = 0; i < 1e9; i++) {
sum += i;
}
return 123;
};
console.log('程式開始執行...');
// 將運算包裹在一個函式中,此時 heavyComputation 還沒被執行
const lazyResult = () => heavyComputation();
console.log('程式的其他部分...');
// 只有當我們真正需要結果時,才呼叫函式來觸發運算
if (false) {
const actualResult = lazyResult(); // 如果這行沒執行,console.log 永遠不會出現
console.log(actualResult);
}
console.log('程式執行結束。');
這個 thunk 技巧顯示了惰性求值的核心精神:將「計算」這個動作本身,變成一個可以傳遞和控制的「值」。但為什麼 Functional Programming 的世界如此重視惰性求值呢?
在像 Haskell 這樣的純函數式程式語言中,惰性求值其實是預設的行為。因為惰性求值與 FP 的核心原則緊密相關,它不僅僅是個效能優化技巧,更是一種思維方式的轉變。
FP 的世界希望純函數(Pure Functions)佔整體程式的比例越多越好,但任何有用的程式最終都必須與外部世界互動,也就是產生副作用,而 FP 管理副作用的方式不是消滅副作用,而是將它們推到系統的邊界,並精確地控制它們的執行時機。
惰性求值正是實現此目標的方式。當一個帶有副作用的計算被惰性化(例如包裹在一個 thunk 或 IO Monad 中),這個副作用並不會立即發生。它變成了一個「待辦事項」,我們可以安全地在純函數的世界裡傳遞、組合這個「待辦事項」,直到最後一刻,在程式的「最外層」才明確地執行它。
延遲執行的特性讓副作用的發生變得可預測且易於追蹤。在一個預設為惰性的語言如 Haskell 中,因為你無法確定一個表達式確切的求值時機,若在其中混入副作用,會導致程式行為變得混亂和不可預測。這種語言特性也幾乎是強迫性的要求開發者必須將純粹的計算與不純的動作分離,進而維護整個系統的純粹性。
惰性求值最直觀的好處,就是避免不必要的計算。如前面 heavyComputation 的例子所示,程式可以只在真正需要結果時才執行。
另一方面來說,惰性求值會改變我們思考資料處理流程的方式。
比較一下同一個操作在「及早求值」與「惰性求值」中的差異。
const result = largeArray
.map(x => x * 2) // 建立一個新的陣列 (中介結果 1)
.filter(x => x > 10) // 再建立一個新的陣列 (中介結果 2)
.find(x => x % 3 === 0) // 在第二個陣列中搜尋
map 的結果,另一個是 filter 的結果。這不僅消耗大量記憶體,也做了許多可能白費的工。如果 largeArray 的第一個元素經過 map 和 filter 後就滿足 find 的條件,那後面 99.9% 的元素運算都是浪費的。map -> filter -> find 的流程。一旦 find 找到滿足條件的元素,整個運算就會立即終止,後續的元素連 map 都不會進入。然而這種優化也有其挑戰。
在及早求值中,如果我們有一個組合函式 f(g(x)),整體的時間複雜度大致就是 O(f) + O(g),相對容易推估。
但在惰性求值中,情況變得更複雜,f 可能只需要從 g(x) 產生的結果中取幾個值,也可能必須遍歷 g(x) 的全部結果,效能表現取決於「實際需求」,使得時間複雜度的分析不再是簡單的加法,而是與資料消費模式緊密相關。這也讓效能分析變得更加困難與不直觀,但換角度來說,這也換來了更大的靈活性與組合性。
(關於惰性求值的時間與空間複雜度,可參考這篇文章)
及早求值要求所有資料都必須完整地存在於記憶體中,這讓「無限」的概念無法實現。然而惰性求值透過「隨需計算」的模式,讓無限資料結構得以實現。
我們可以定義一個代表所有自然數、所有費波那契數、或所有質數的「無限列表」。這在數學上是很自然的概念,在惰性求值的程式語言中也同樣能表達。
-- 定義一個無限的自然數列表
naturalNumbers = [1..] -- 代表 1, 2, 3, ... 無限延伸
-- 取出前 10 個自然數
firstTenNaturals = take 10 naturalNumbers
-- 測試印出結果
main :: IO ()
main = print firstTenNaturals -- 取出前 10 個,結果是 [1,2,3,4,5,6,7,8,9,10]
這段 Haskell 程式實現「關注點分離」:一個函式負責生成資料(它可以是無限的),另一個函式負責消費資料(它決定需要多少)。生成者無需知道何時停止,消費者也無需關心資料是如何生成的。這種模組化和可組合性,是 FP 所追求的核心原則。
以下簡單比較兩種求值策略:
| 特性 | Eager Evaluation (及早求值) | Lazy Evaluation (惰性求值) |
|---|---|---|
| 執行時機 | 立即計算,表達式一旦綁定就求值 | 延遲到真正需要用到值時才計算 |
| 資源使用 | 可能在不必要的計算上浪費 CPU/記憶體 | 僅在需要時計算,可避免不必要的運算與中介資料 |
| 控制流程 | 簡單、可預測、線性 | 非線性,由需求驅動,控制較複雜 |
| 無限資料 | 無法處理 | 原生支援,可操作無限序列 |
| 副作用 | 立即發生(難以推遲) | 延遲到求值時才發生,方便隔離副作用 |
| 優點 | 簡單直觀、容易除錯 | 更容易組合,支援無限結構,副作用可控 |
| 缺點 | 可能浪費資源,無法處理無限結構 | 程式流程較難追蹤,除錯不直觀 |
| 適用場景 | 一般命令式程式設計、大多數日常計算、需要立即結果的情境 | Functional Programming(IO/Task 等)、串流處理、大型資料集、需要控制副作用或處理無限序列時 |
了解了惰性求值為何對 FP 很重要之後,來看看在 JavaScript 中如何實現它。在 JavaScript 中,generator function 可實現惰性求值,只在需要時呼叫並運算、得到值。而在認識 generator function 之前,我們需要先理解建立在 generator function 之上的迭代協議(Iteration Protocols),理解 Iteration 才能進一步理解 generator function 的運作原理。
我們會用 for...of 迴圈來遍歷 Array、String、Map、Set 等型別的資料,但為什麼不能直接用在一個普通的 Object 上呢?
// ✅ Array 可以被迭代
for (const item of [1, 2, 3]) {
console.log("Array item:", item);
}
// ✅ String 可以被迭代
for (const char of "hello") {
console.log("String char:", char);
}
// ✅ Map 可以被迭代
const map = new Map([["a", 1], ["b", 2]]);
for (const [key, value] of map) {
console.log("Map entry:", key, value);
}
// ✅ Set 可以被迭代
const set = new Set([1, 2, 3]);
for (const value of set) {
console.log("Set value:", value);
}
const obj = { a: 1, b: 2 };
// ❌ Object 無法被迭代
for (const prop of obj) {
console.log(prop);
}
// Uncaught TypeError: obj is not iterable
答案就在於「可迭代協議(Iterable Protocol)」。這個協議規定,一個物件若要被視為「可迭代的(iterable)」,它必須實作一個特殊的屬性鍵:[Symbol.iterator]。
這個屬性本身必須是一個函式,當它被呼叫時,會回傳一個「迭代器(iterator)」物件。[Symbol.iterator] 這屬性會告訴 JavaScript 引擎:「我知道如何提供一個序列,你可以用 for...of 來問我拿資料。」
可以試著驗證看看:
console.log(typeof [][Symbol.iterator]); // "function"
console.log(typeof "hello"[Symbol.iterator]); // "function"
console.log(typeof new Map()[Symbol.iterator]); // "function"
console.log(typeof {}[Symbol.iterator]); // "undefined"
當 for...of 或其他迭代語法(例如展開運算子 ...)作用於一個可迭代物件時,它會先呼叫該物件的 [Symbol.iterator]() 方法,取得一個迭代器(iterator)物件。(補充:可迭代物件意思就是具有 [Symbol.iterator] 屬性,且該屬性是一個函式的物件)
這個迭代器物件才是真正負責「一步一步提供資料」的角色。
「迭代器協議(Iterator Protocol)」規定,迭代器物件必須實作一個 next() 方法,每次呼叫 next(),都必須回傳一個 IteratorResult 物件,包含兩個屬性:
value: 這次迭代所產生的值。done: 一個布林值。如果為 false,表示迭代還沒結束,後面還有值;如果為 true,表示迭代已經結束。我們可以手動模擬一下 for...of 的執行過程,來理解這中間發生什麼事:
const arr = ['a', 'b'];
// 取得迭代器
const iterator = arr[Symbol.iterator]();
console.log(iterator.next()); // { value: 'a', done: false }
console.log(iterator.next()); // { value: 'b', done: false }
console.log(iterator.next()); // { value: undefined, done: true }
for...of 迴圈的內部機制就是不斷地呼叫 next(),並將回傳物件中的 value 取出,直到 done 變為 true 為止。
在 JavaScript 中,物件本身並不是可迭代的,所以無法直接用 for...of。但只要我們在物件上實作 Iterable Protocol(即定義一個 [Symbol.iterator] 方法),它就能被視為可迭代物件。
這個 [Symbol.iterator] 方法必須回傳一個符合 Iterator Protocol 的迭代器物件,而這個迭代器必須實作 next() 方法,並在每次呼叫時回傳一個 { value, done } 結構。
現在來看看實作內容:
const person = {
name: 'Monica',
hobbies: ['coding', 'reading', 'gaming'],
// 定義 [Symbol.iterator],讓 person 變成 iterable
[Symbol.iterator]: function() {
let index = 0;
const hobbies = this.hobbies;
// 返回一個迭代器物件
return {
// 迭代器協議要求必須有 next() 方法
next: function() {
if (index < hobbies.length) {
return {
value: hobbies[index++],
done: false
};
} else {
return {
value: undefined,
done: true
};
}
}
};
}
};
// 現在 person 物件可以被 for...of 迭代
for (const hobby of person) {
console.log(hobby);
}
// 輸出:
// coding
// reading
// gaming
這個實作的過程顯示了迭代協議的本質,它是一個統一的抽象介面,將「資料的消費者」(如 for...of 迴圈)與「資料的生產者」(如 Array、String 或我們自訂的 person 物件)解耦。
也補充個示意圖說明 Iterator 的運作流程,簡單講就是執行 [Symbol.iterator]()之後,會取得 iterator 物件,然後針對 iterator 重複執行 next(),就會得到 { value, done }。
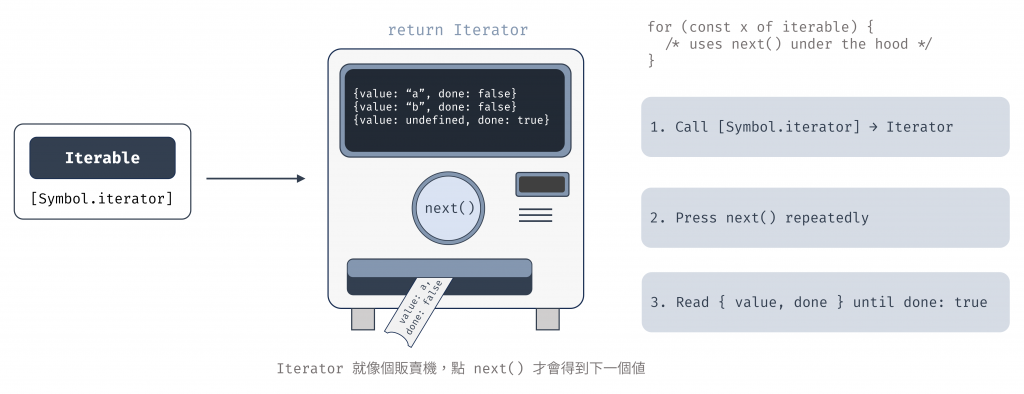
圖 1 Iterator 的運作流程示意圖(資料來源: 自行繪製)
在前面 person 物件的例子中,我們透過手動實作迭代協議(Iterable Protocol) 來讓物件可以被 for...of 迭代呼叫,這需要自行管理狀態(例如 index),並在每次呼叫 next() 時手動建構 { value, done } 物件。雖然可行,但程式碼冗長,維護成本高,而且容易出錯。
這正是 Generator function 存在的價值,Generator 提供了一種優雅的語法,讓我們能以更直觀的方式定義迭代行為,而無需處理狀態管理與 next() 的細節。
Generator 與 Iterator 的關係可以這樣理解:
next() 方法,因此可以直接搭配 for...of 使用。換句話說,Generator function 就是一個「迭代器工廠」。
了解了 Generator function 作為迭代器工廠的角色後,終於可以來看看 Generator function 是什麼。它不僅是撰寫迭代器的語法糖,更是 JavaScript 中實現惰性求值的核心工具。
Generator function 在語法上有兩個特徵:
function* 關鍵字來宣告yield 關鍵字來「產出」值最關鍵的是,呼叫一個 Generator function 並不會立即執行它內部的程式碼。相反地,它會立刻回傳一個 Generator 物件 。這個 Generator 物件本身就是一個迭代器,符合上面提到的迭代器協議。
來看一個簡單的例子:
function* threeStepGenerator() {
console.log('Step 1: 執行');
yield 1;
console.log('Step 2: 執行');
yield 2;
console.log('Step 3: 執行');
yield 3;
console.log('執行完畢');
}
// 呼叫 Generator function,注意此時沒有任何 console.log 被印出
const gen = threeStepGenerator();
console.log('Generator 已建立');
// gen 就是一個迭代器,我們來手動呼叫 next()
console.log(gen.next()); // Step 1: 執行, { value: 1, done: false }
console.log(gen.next()); // Step 2: 執行, { value: 2, done: false }
console.log(gen.next()); // Step 3: 執行, { value: 3, done: false }
console.log(gen.next()); // 執行完畢, { value: undefined, done: true }
執行流程解析如下:
const gen = threeStepGenerator(): 函式被呼叫,但內部程式碼完全沒有執行。gen 變數現在是一個處於「暫停」狀態的迭代器。gen.next(): 程式碼從函式開頭開始執行,直到遇到第一個 yield。它會印出 "Step 1: 執行",然後將 yield 後面的值 1 作為 value 回傳,並暫停執行。gen.next(): 程式碼從上次暫停的地方(第一個 yield 之後)繼續執行,直到遇到第二個 yield。它印出 "Step 2: 執行",回傳 { value: 2, done: false },然後再次暫停。next() 呼叫會讓程式碼從最後一個 yield 之後執行到函式結尾,並回傳 { value: undefined, done: true }。yield 關鍵字就像是函式執行中的一個個「暫停點」。函式的執行權在呼叫者(呼叫 next() 的地方)和 Generator 之間來回切換。
這種「暫停與恢復」的行為,讓 JavaScript 能實現惰性求值的機制。Generator 只在我們透過 next() 明確要求時,才會執行計算並產出下一個值。
現在我們就可用 JavaScript 來實現 Haskell 中的「無限自然數列表」:
// 建立一個「無限」的自然數生成器
function* createNaturalNumbers() {
let i = 1;
while (true) {
yield i++;
}
}
const numbers = createNaturalNumbers();
// 手動呼叫 next(),一次要一個數字
console.log(numbers.next().value); // 1
console.log(numbers.next().value); // 2
console.log(numbers.next().value); // 3
// ...可以一直呼叫下去
更常見的方式是搭配 for...of 使用:
// 注意:一定要有 break 條件,否則會進入無限迴圈!
for (const num of numbers) {
if (num > 10) break;
console.log(num); // 依序輸出 1 ~ 10
}
在 createNaturalNumbers 函式中,while (true) 沒有讓瀏覽起卡死進入無窮迴圈,關鍵就在於惰性求值,因為 createNaturalNumbers 函式並沒有試圖一次性產生所有數字,它只是建立了一個「承諾」:只要你呼叫 next(),我就能給你下一個自然數。只在需要時才索取,避免了不必要的計算和無限的記憶體消耗。
next(value) 的雙向溝通yield 不僅僅是一個單向的「產出」指令,它更是一個可以接收值的「表達式」。只要向 next() 方法傳遞參數,呼叫者就可以將資料傳回給 Generator,影響它後續的行為。
有點微妙的點是,第一次呼叫 next() 的參數會被忽略,因為此時函式尚未執行到第一個 yield,還沒有位置能接收值。從第二次開始,傳入的參數才會真正進入 Generator,作為上一次 yield 的結果。
function* quizGenerator() {
const answer1 = yield '2 + 2 = ?';
console.log(`你對第一題的回答是: ${answer1}`);
if (answer1 !== 4) {
yield '答錯了!';
return; // 結束
}
const answer2 = yield '10 + 5 = ?';
console.log(`你對第二題的回答是: ${answer2}`);
if (answer2 !== 15) {
yield '答錯了!';
} else {
yield '恭喜你全部答對!';
}
}
const quiz = quizGenerator();
// 啟動 Generator,取得第一個問題
console.log(quiz.next().value); // '2 + 2 = ?'
// 傳入第一題的答案 (4)
console.log(quiz.next(4).value);
// 輸出: 你對第一題的回答是: 4
// 回傳: '10 + 5 = ?'
// 傳入第二題的錯誤答案 (99)
console.log(quiz.next(99).value);
// 輸出: 你對第二題的回答是: 99
// 回傳: '答錯了!'
這種雙向溝通的能力,讓 Generator 從一個單純的「懶人資料生產者」變成一個強大的「協程(Coroutine)」。它就像一個可以暫停和恢復的獨立計算單元,能夠與主程式進行協作。
在 async/await 普及之前,正是利用這種特性,許多框架(例如 co)用 Generator + yield 來把非同步流程寫成看起來像同步的直線程式碼。
co(fn*) 會充當「執行器」:它逐步執行 generator,每遇到一個 yield 就暫停,等待該值完成,然後把結果回填為上一個 yield 表達式的回傳值再繼續往下跑。被 yield 的東西(稱作 yieldables)可以是 Promise、thunk(單一 callback 的函式)、陣列/物件(代表平行執行並聚合結果)、甚至是另一個 generator(委派)。
且整個 co() 會回傳一個 Promise,因此可以用 then 或 catch 串接,也能在 generator 內用 try/catch 直接捕捉非同步錯誤。這種以「暫停/恢復」為核心的協程式(coroutine-like)編排,消除了回呼巢狀(Callback Hell)、讓錯誤處理與資源釋放更一致,也為後來的 async/await 奠定了心智模型:async 函式約等於 generator + 執行器,await 則約等於 yield 等待 Promise 完成;甚至 co.wrap 還能把 generator 包成回傳 Promise 的一般函式,便於與既有 API 無縫整合。
更多詳細可見 co 的 github,雖然現在開發不會使用這套件,但多了解以前開發者如何解決非同步 Callback Hell 問題也蠻有趣的!
return() 與 throw()除了 next(),Generator 物件還提供了兩個方法,讓外部呼叫者可以更精細地控制其生命週期:
iterator.return(value): 讓呼叫者可以強制終止 Generator。Generator 會立即進入 done: true 狀態,並將 return 的值作為 value。這就像是在說:「我不需要後面的值了,你可以提前結束並清理資源。」。iterator.throw(error): 可以在 Generator 暫停的地方注入一個錯誤。如果 Generator 內部有 try...catch 區塊,這個錯誤可以被捕捉;否則,錯誤會被拋出,Generator 同樣會終止。更多說明可參考 PJ 大大寫的文章。以下是今天的幾個重點。
一種延遲計算的策略,直到值被真正需要時才執行。這在函數式程式設計 (FP) 中是管理副作用、優化效能,以及構建無限資料結構的關鍵工具。
JavaScript 提供了統一的規範來存取序列型資料。任何物件只要實作了 [Symbol.iterator] 方法,就能被視為可迭代物件 (Iterable),並與 for...of、展開運算子等語法搭配使用。
建立迭代器的原生語法讓 JavaScript 能實現惰性求值。呼叫 Generator 函數不會立刻執行,而是回傳一個 Generator 物件,它本身就是迭代器,能與 for...of 結合使用。
yield 關鍵字是 Generator function 的核心語法。它會暫停函式執行,將值傳回呼叫者,並等待下一次 .next() 呼叫後再從暫停點繼續。
Generator 只在需要時才產生值,因此能有效降低記憶體消耗,並在 JavaScript 中優雅地表達像「無限序列」這類在 FP 中常見的強大概念。
除了單純的迭代,Generator 還能透過 .next(value) 接收外部傳入的值,實現雙向溝通。這讓它成為一種輕量的協程機制,可用於管理狀態繁複的流程。在 async/await 出現之前,這種能力甚至支撐了像 co 這類框架,用來解決「回呼地獄 (Callback Hell)」。
